
{kind=link}

Xiaomi MiMo team publicly released two new models: MiMo-V2.5-Pro and MiMo-V2.5. The benchmarks, combined with some genuinely striking real-world task demos, make a compelling case that open agentic AI is catching up to the frontier faster than most expected. Both models are available immediately via API, and priced competitively.
What is an Agentic Model, and Why Does It Matter?
Most LLM benchmarks test a model’s ability to answer a single, self-contained question. Agentic benchmarks test something much harder — whether a model can complete a multi-step goal autonomously, using tools (web search, code execution, file I/O, API calls) over many turns, without losing track of the original objective.
Think of it as the difference between a model that can answer “how do I write a lexer?” versus one that can actually write a complete compiler, run tests against it, catch regressions, and fix them — all without a human in the loop. The latter is exactly what Xiaomi MiMo team is demonstrating here.
MiMo-V2.5-Pro: The Flagship
MiMo-V2.5-Pro is Xiaomi’s most capable model to date, delivering significant improvements over its predecessor, MiMo-V2-Pro, in general agentic capabilities, complex software engineering, and long-horizon tasks.

The key benchmark numbers are competitive with top closed-source models: SWE-bench Pro 57.2, Claw-Eval 63.8, and τ3-Bench 72.9 — placing it alongside Claude Opus 4.6 and GPT-5.4 across most evaluations. V2.5-Pro can sustain complex, long-horizon tasks spanning more than a thousand tool calls, demonstrating substantial improvements in instruction following within agentic scenarios, reliably adhering to subtle requirements embedded in context and maintaining strong coherence across ultra-long contexts.
One behavioral property that distinguishes V2.5-Pro from earlier models is what Xiaomi MiMo team calls “harness awareness”: it makes full use of the affordances of its harness environment, manages its memory, and shapes how its own context is populated toward the final objective. This means the model doesn’t just execute instructions mechanically. It actively optimizes its own working environment to stay on track across very long tasks.
The three real-world task demos Xiaomi published illustrate exactly what “long-horizon agentic capability” means in practice.
Demo 1 — SysY Compiler in Rust: Referred from Peking University’s Compiler Principles course project, this task asks the model to implement a complete SysY compiler in Rust from scratch: lexer, parser, AST, Koopa IR codegen, RISC-V assembly backend, and performance optimization. The reference project typically takes a PKU CS major student several weeks. MiMo-V2.5-Pro finished in 4.3 hours across 672 tool calls, scoring a perfect 233/233 against the course’s hidden test suite.
What’s notable isn’t just the final score — it’s the architecture of execution. Rather than thrashing through trial and error, the model built the compiler layer by layer: scaffold the full pipeline first, perfect Koopa IR (110/110), then the RISC-V backend (103/103), then performance (20/20). The first compile alone passed 137/233 tests, a 59% cold start that suggests the architecture was designed correctly before a single test was run. When a refactoring step later caused regressions, the model diagnosed the failures, recovered, and pushed on. This is structured, self-correcting engineering behavior — not pattern-matched code generation.
Demo 2 — Full-Featured Desktop Video Editor: With just a few simple prompts, MiMo-V2.5-Pro delivered a working desktop app: multi-track timeline, clip trimming, cross-fades, audio mixing, and export pipeline. The final build is 8,192 lines of code, produced over 1,868 tool calls across 11.5 hours of autonomous work.
Demo 3 — Analog EDA- FVF-LDO Design: This is the most technically specialized demo: a graduate-level analog-circuit EDA task requiring the design and optimization of a complete FVF-LDO (Flipped-Voltage-Follower low-dropout regulator) from scratch in the TSMC 180nm CMOS process. The model had to size the power transistor, tune the compensation network, and pick bias voltages so that six metrics land within spec simultaneously — phase margin, line regulation, load regulation, quiescent current, PSRR, and transient response. Wired into an ngspice simulation loop, in about an hour of closed-loop iteration — calling the simulator, reading waveforms, tweaking parameters — the model produced a design where every target metric is met, with four key metrics improved by an order of magnitude over its own initial attempt.
Token Efficiency: Intelligence at frontier level is only useful if it’s cost-effective. On ClawEval, V2.5-Pro lands at 64% Pass^3 using only ~70K tokens per trajectory — roughly 40–60% fewer tokens than Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4 at comparable capability levels. For engineers building production agent pipelines, this is a material cost reduction, not just a marketing stat.
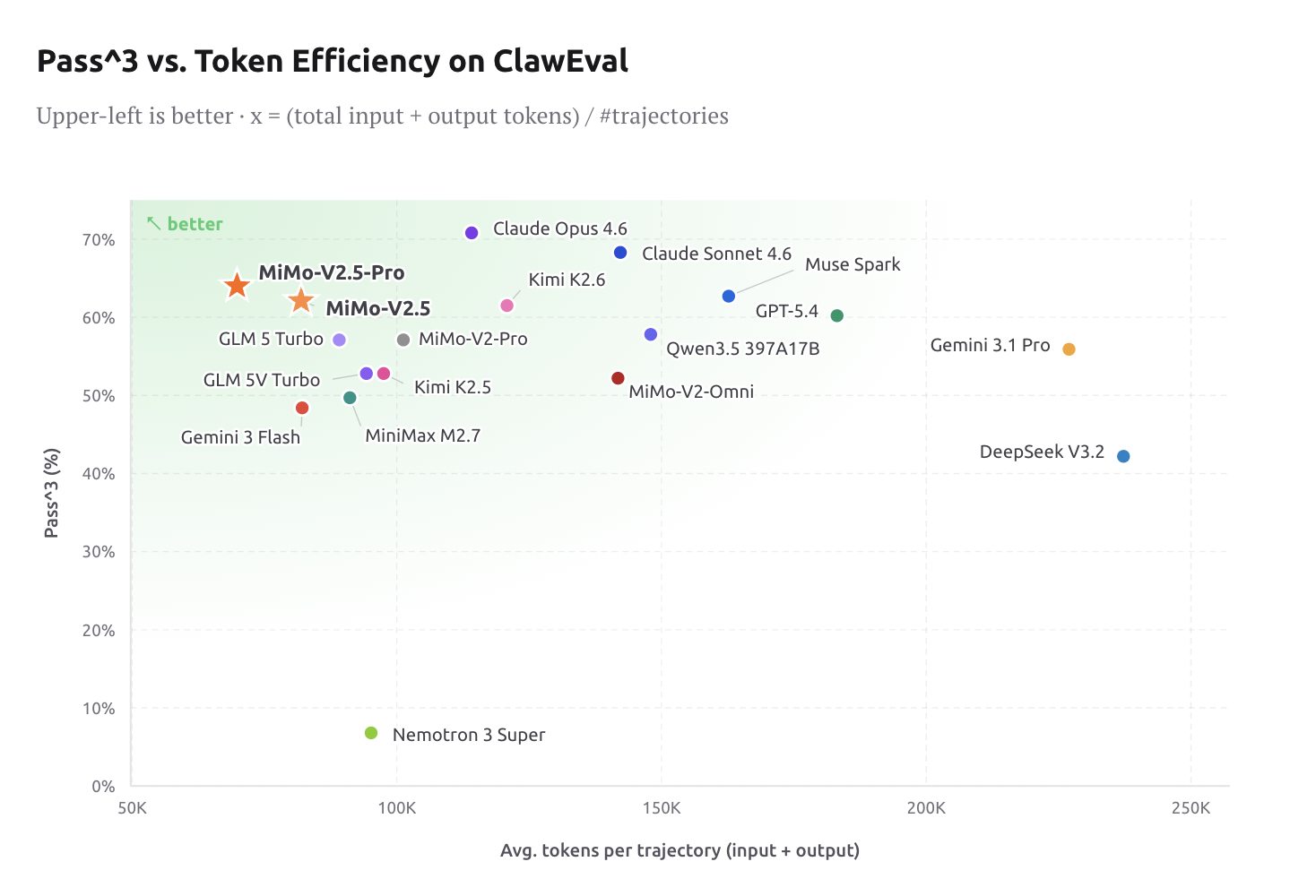
MiMo Coding Bench is Xiaomi’s in-house evaluation suite designed to assess models on real-world developer tasks within agentic frameworks like Claude Code. It covers repo understanding, project building, code review, structured artifact generation, planning, SWE, and more. V2.5-Pro leads the field on this benchmark, and Xiaomi explicitly positions it as a drop-in backend for scaffolds including Claude Code, OpenCode, and Kilo.
MiMo-V2.5: Native Omnimodal at Half the Cost
While V2.5-Pro targets the hardest long-horizon agentic tasks, MiMo-V2.5 is a major step forward in agentic capability and multimodal understanding. With native visual and audio understanding, MiMo-V2.5 reasons seamlessly across modalities, surpasses MiMo-V2-Pro in agentic performance, and supports up to 1 million tokens of context.
The model is designed with perception and action unified from scratch. MiMo-V2.5 is trained from the start to see, hear, and act on what it perceives, leading to a single model that understands everything and gets things done. This is architecturally significant — earlier multimodal models often bolted vision on top of a text backbone, creating capability gaps at the perception-action boundary.
On the coding side, the value proposition is clear: in MiMo Coding Bench, MiMo-V2.5 delivers strong results on everyday coding tasks, closing the gap with frontier models and matching MiMo-V2.5-Pro at half the cost. For teams that don’t need the extreme long-horizon depth of V2.5-Pro, this is a compelling operating point.
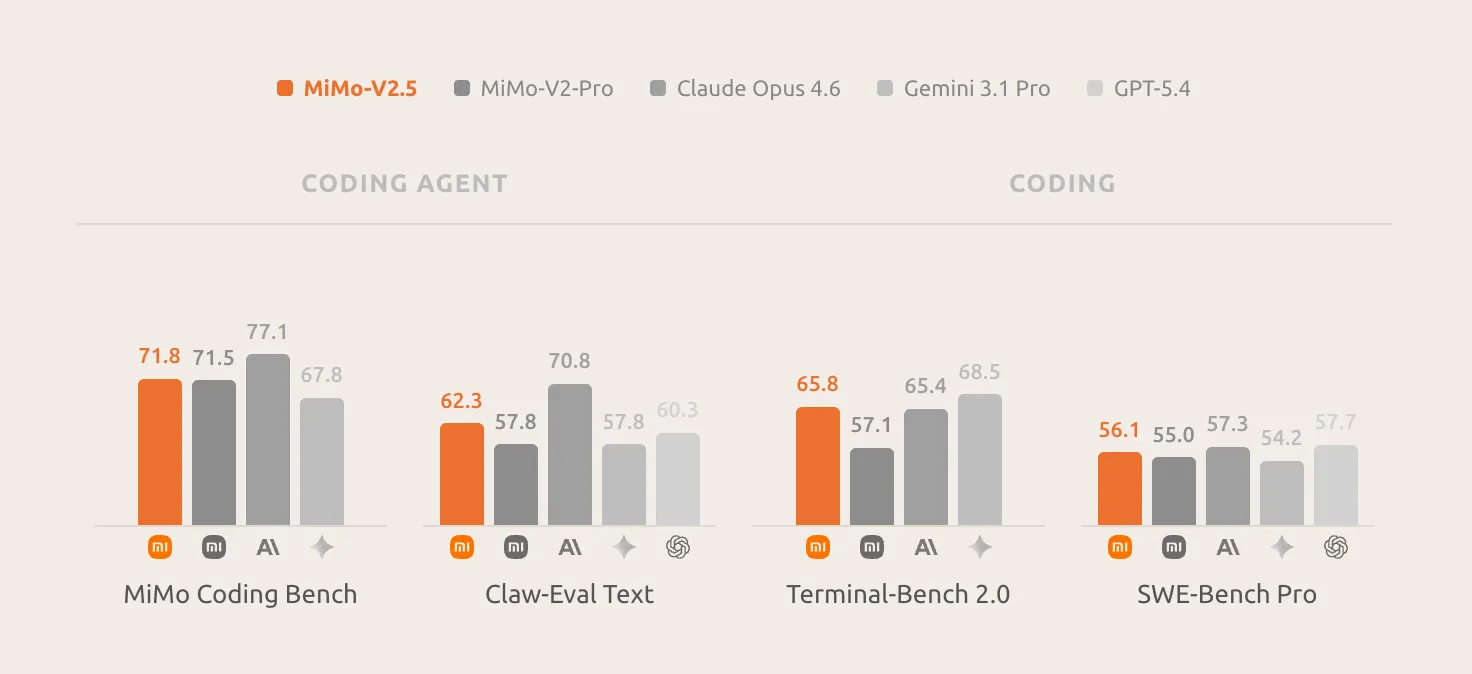
On multimodal benchmarks: MiMo-V2.5 achieves a 62.3 on the Claw-Eval general subset, placing it at the Pareto frontier of performance and efficiency. On the multimodal agentic subset, MiMo-V2.5 reaches 23.8 on Claw-Eval Multimodal, matching Claude Sonnet 4.6, leading MiMo-V2-Omni by eight points, and trailing Claude Opus 4.6 by a single point.
On video understanding, MiMo-V2.5 scores 87.7 on Video-MME, effectively tied with Gemini 3 Pro (88.4) and well ahead of Gemini 3 Flash. Long-horizon video comprehension — scene tracking, temporal reasoning, visual grounding over minutes of footage — is now in frontier territory. On image understanding, MiMo-V2.5 lands at 81.0 on CharXiv RQ and 77.9 on MMMU-Pro, closing in on Gemini 3 Pro.
Pricing is straightforward: MiMo-V2.5 runs at 1x (1 token = 1 credit), while MiMo-V2.5-Pro runs at 2x (1 token = 2 credits). Token Plans no longer charge a multiplier for the 1M-token context window — previously a common cost friction for long-context agentic workloads.
Key Takeaways
- MiMo-V2.5-Pro matches frontier closed-source models on key agentic benchmarks (SWE-bench Pro 57.2, Claw-Eval 63.8, τ3-Bench 72.9), while using 40–60% fewer tokens per trajectory than Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4.
- Long-horizon autonomy is real and measurable — V2.5-Pro autonomously built a complete SysY compiler in Rust (233/233 tests, 672 tool calls, 4.3 hours) and a full-featured desktop video editor (8,192 lines of code, 1,868 tool calls, 11.5 hours).
- MiMo-V2.5 is natively omnimodal — trained from scratch to see, hear, and act across modalities with a native 1M-token context window, matching Claude Sonnet 4.6 on Claw-Eval Multimodal and nearly tying Gemini 3 Pro on Video-MME (87.7 vs. 88.4).
- Pro-level coding performance at half the cost — on MiMo Coding Bench, MiMo-V2.5 matches MiMo-V2.5-Pro on everyday coding tasks at 1x token pricing, making it the practical choice for most production agent pipelines.
- Both models are already compatible with popular agentic scaffolds like Claude Code, OpenCode, and Kilo — giving AI devs a drop-in, auditable, self-hostable path to frontier-level agentic AI.
Check out the Technical details MiMo-V2.5, and Technical details MiMo-V2.5-Pro. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us